インタラクティブPDF・字幕翻訳デモ:書式を保持した翻訳をその場で体験
サインアップ不要で、AI搭載のPDF翻訳と字幕翻訳をお試しください。Doc2Langが100以上の言語でフォント、表、レイアウト、タイミングコードをどのように保持するかをご覧いただけます。
2026年4月8日公開 · 8分で読了 · Doc2Langチーム
要約
私たちはdoc2lang.comでインタラクティブな翻訳デモを公開しました。ファイルのアップロードやサインアップなしで、AI搭載のPDF翻訳およびAI字幕翻訳をお試しいただけます。サンプルドキュメントを選び、100以上の対応言語から翻訳先を選ぶと、フォント・表・レイアウト・タイミングコードが実際の出力でどのように保持されるかをオリジナルと並べて確認できます。この記事では、なぜこのデモを作ったのか、書式を保持するドキュメント翻訳が実際にどのように動作しているのか、そして次に何が来るのかを解説します。
ジャンプ先:
- 2026年のオンラインPDF翻訳の現状
- なぜインタラクティブデモを作ったのか
- Doc2LangのPDF翻訳はどうやって書式を保持するのか
- デモの流れ:3クリックで「すごい」と言わせる
- Doc2Langの字幕翻訳はどうやってタイミングコードを保持するのか
- Doc2Langデモを試してみよう
- 次に予定していること
- よくある質問
2026年のオンラインPDF翻訳の現状
Googleで「PDF オンライン 翻訳」と検索すれば、何十もの結果が表示されます。「PDF 日本語 翻訳」や「SRT 字幕 翻訳」と検索すれば、さらに何十も出てきます。そのほとんどは次のように動作します:
- ファイルをアップロード
- 待つ
- 書式のない、ぐちゃぐちゃのプレーンテキストを受け取る
- Wordで2時間かけてレイアウトを作り直す
これがAIドキュメント翻訳の汚い秘密です。翻訳そのものはほぼ解決されていますが、書式保持の部分は解決されていません。GPT-4やClaudeのような大規模言語モデルは、言語間をほぼ人間並みの精度で翻訳できます。難しいのは言葉ではなく、言葉を入れ替えている間にドキュメントの構造をそのまま保つことです。
一般的なPDFには以下のものが含まれます:
- 正確なx/y座標に配置されたテキスト
- 翻訳先言語に対応するものが存在しない可能性のあるフォント
- 見えないグリッド線と整列されたテキストボックスで作られた表
- キャプションが埋め込まれた画像
- 読み取り順序のメタデータを持つ複数カラムのレイアウト
- ヘッダー、フッター、ページ番号、脚注
- ベクターグラフィックス、チャート、インライン数式
単純なPDF翻訳ツールがテキストを抽出して翻訳APIに送り、それを貼り戻すと、これらの構造はすべて失われます。さらに悪いことに、翻訳されたテキストはほぼ常に元の長さと異なります。日本語はおおよそ英語の60%の長さ、ドイツ語はおおよそ130%です。そのため、座標を保持しても、テキストがはみ出したり隙間ができたりします。
これがDoc2Langが過去2年間取り組んできた問題です。そして、私たちが先日公開したデモは、訪問者が初めて、何もコミットすることなくリアルタイムで解決策の動作を見ることができる場となります。
なぜインタラクティブデモを作ったのか(そしてあなたも作るべき理由)
Doc2Langの旧ランディングページはこのようなものでした:
シンプル。機能的。何をすべきか明確。それでも、私たちの分析データは残酷な事実を物語っていました。ほとんどの訪問者は15秒以内に離脱。残った訪問者もアップロード段階で離脱することが多かったのです。アップロードを完了した一握りの訪問者は良いコンバージョン率を示しましたが、それより上のファネルは至るところで漏れていました。
ユーザーに話を聞きました。フィードバックは一貫していました:
今月だけで他のPDF翻訳ツールを5つ試しました。どれも書式を保持すると謳っていました。どれも実現できていませんでした。なぜあなたたちにもう一つファイルを無駄にする必要があるのですか?
もっともです。このカテゴリーでは信頼が崩壊しており、コピーライティングでは修復できません。そこで私たちは、開始するのに信頼を一切必要としない体験を構築しました。それがインタラクティブ翻訳デモです。
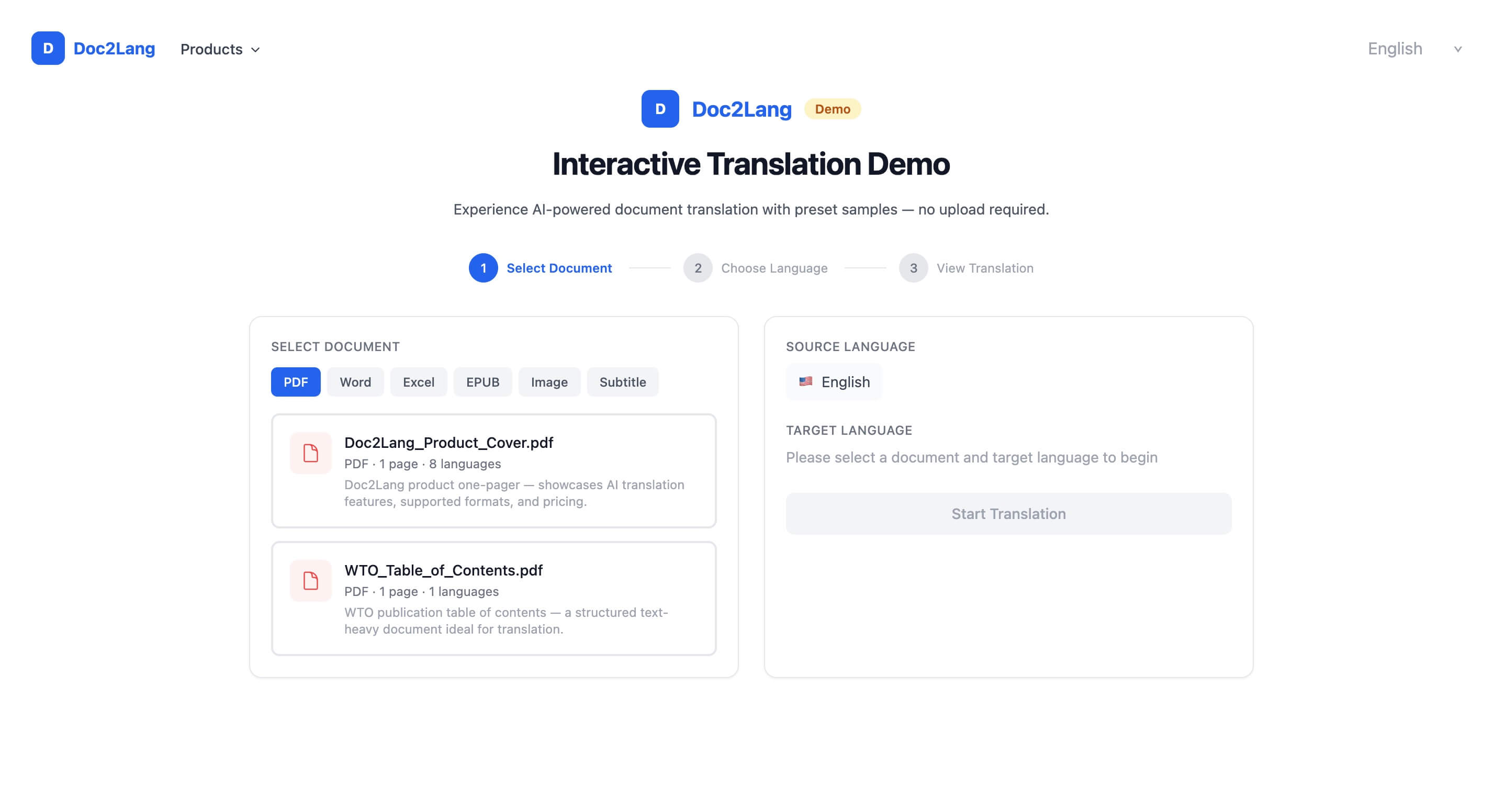
原則はシンプルです。何かを求める前に、まず製品を体験してもらうこと。サインアップなし、アップロードなし、メール認証なし。事前に読み込まれたサンプルドキュメント、3クリック、即座に結果表示。
Doc2LangのPDF翻訳はどうやって書式を保持するのか
少し技術的な話をしましょう。ここはほとんどのブログ記事が素通りする部分だからです。
Doc2LangがPDFを翻訳のために処理するとき、単にテキストを抽出して翻訳するわけではありません。マルチステージのパイプラインを実行します:
ステージ1:ドキュメント解析
PDFをレイアウト要素の構造化されたツリー(テキストブロック、表、画像、ベクターグラフィックス)に解析します。それぞれの位置、サイズ、フォント、色、z-indexが保持されます。これはOCRではありません。ネイティブPDFの場合は実際のドキュメント構造を読み取ります。スキャンされたPDFの場合は、レイアウトを意識したOCRパスにフォールバックします。
ステージ2:セマンティックグルーピング
一緒に属する隣接するテキストブロック(2カラムにまたがる段落や、見出しとその小見出しなど)は意味的にグループ化されます。これが重要なのは、各ブロックを単独で翻訳すると意味不明な結果になるからです。文脈がすべてです。
ステージ3:レイアウト制約付きの翻訳
各セマンティックグループは、明示的な制約付きでLLMによって翻訳されます。「この段落を日本語に翻訳してください。ただし、結果はこのフォントを使用してこれだけのピクセル幅のボックスに収まらなければなりません」といった具合です。モデルは利用可能なスペースに収まる表現を選ぶよう指示されます。見出しの場合、これは多くの場合より短い同義語を選ぶことを意味します。本文の場合は、文の再構成を意味することもあります。
ステージ4:フォント置換
元のPDFが翻訳先言語の文字セットをサポートしないフォント(例:日本語のレンダリングを求められるラテン文字専用フォント)を使用している場合、私たちは視覚的に最も近く、かつ対応しているフォントに置き換えます。これが、私たちの日本語翻訳がデフォルトのシステムフォントのように見えない理由です。オリジナルとの視覚的連続性を維持しています。
ステージ5:再レンダリング
最後に、翻訳されたテキスト、オリジナルの画像、オリジナルのベクターグラフィックス、調整されたレイアウトボックスを使用して、PDFをゼロから再レンダリングします。出力はAdobe Acrobatで開ける本物のPDFファイルであり、そのスクリーンショットではありません。
デモで実際の結果をご覧いただけます:
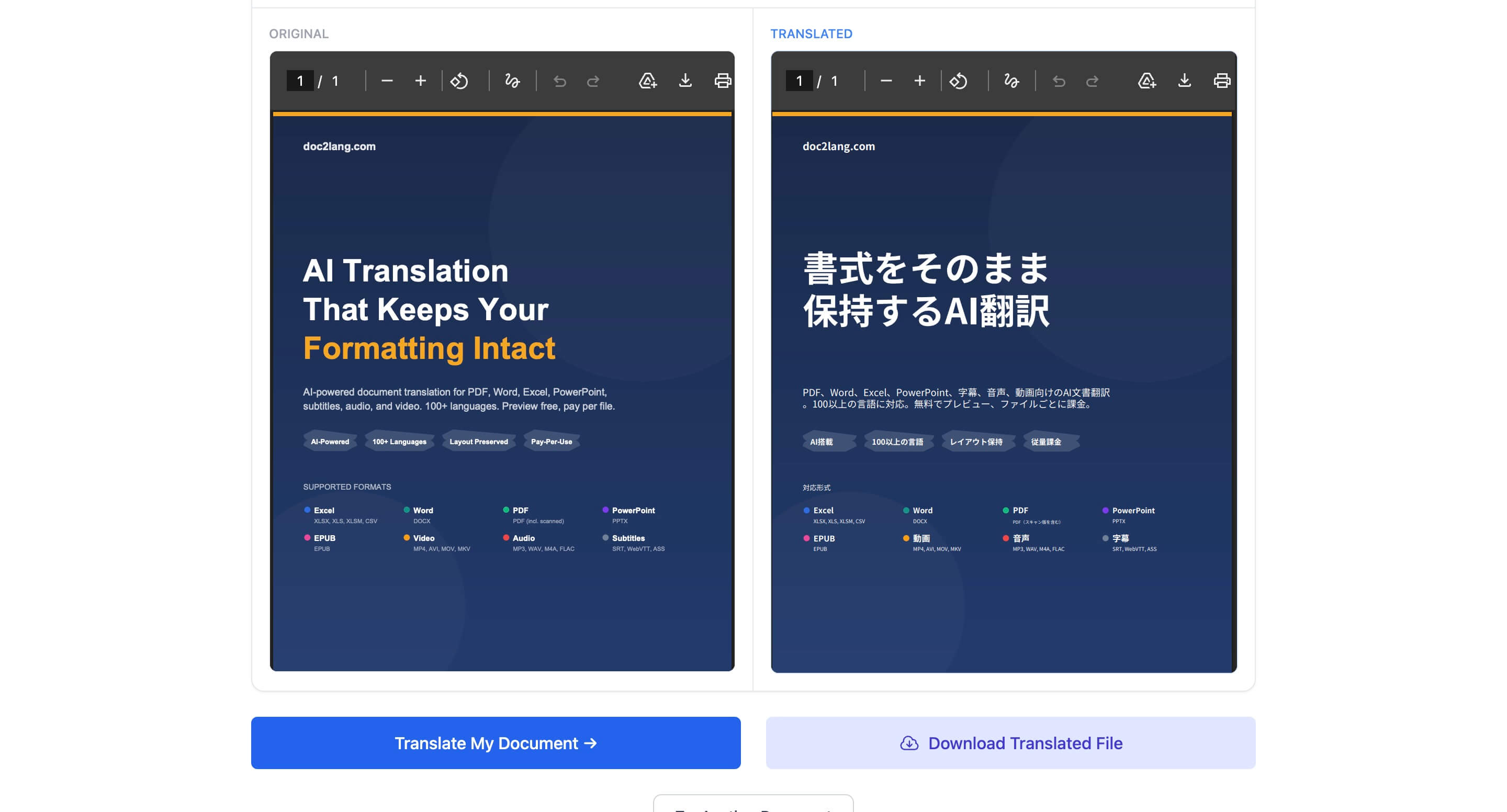
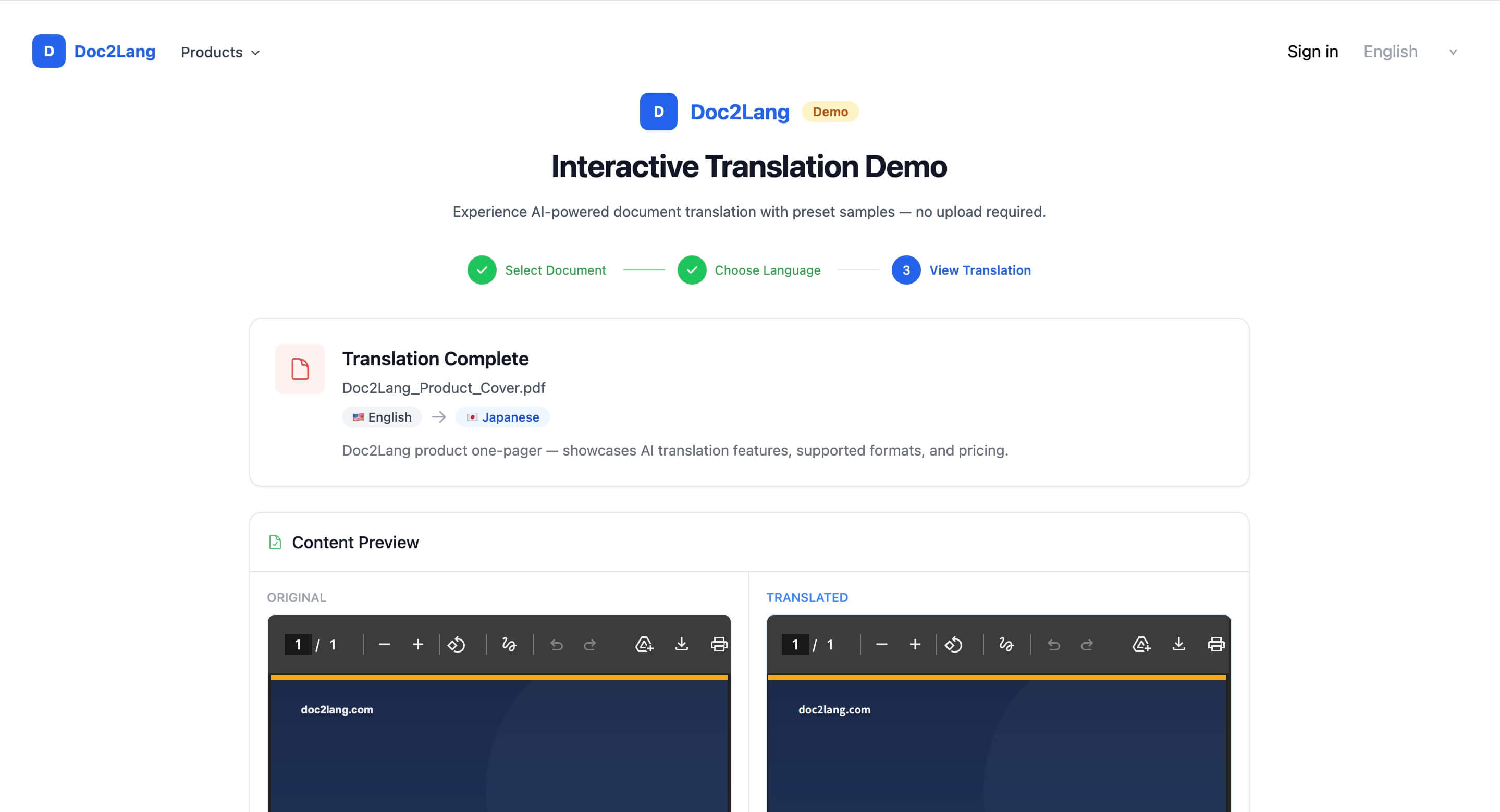
左の英語版には濃紺のヒーローセクション、オレンジのアクセント、4つの機能ピル、色付き箇条書きの対応フォーマットグリッドがあります。右の日本語版では、これらの主要な視覚構造を保ちながら日本語の長さに合わせて文字を再配置しています。機能ピルは「AI搭載」「100以上の言語」「レイアウト保持」「従量課金」と表示されます。
このサンプルは書式保持PDF翻訳の実際の出力例です。主要な視覚要素は元の位置関係を保っていますが、PDFの内部構造、フォント、訳文の長さによって結果は異なります。デモから日本語版PDFをダウンロードして直接確認できます。
デモの流れ:3クリックで「すごい」と言わせる
私たちはこのデモを意図的にフォームの正反対になるよう設計しました。3ステップ、摩擦ゼロ:
ステップ1:サンプルドキュメントを選ぶ。 現実世界の課題を示すファイルを事前に読み込んであります。複雑なレイアウトの製品1ページャー(Doc2Lang_Product_Cover.pdf)、構造化されたテキスト中心のWTO出版物の目次(WTO_Table_of_Contents.pdf)、そしてBlenderのオープンムービー字幕ファイル(Sprite Fright.srt)です。これらは玩具のような例ではなく、実際のエッジケースです。
ステップ2:翻訳先言語を選ぶ。 PDF翻訳と字幕翻訳の両方で100以上の言語に対応しています。デモでは、最も人気のある8つの言語を国旗の絵文字付きクリック可能なボタンとして表示します:中国語、日本語、韓国語、スペイン語、フランス語、ドイツ語、イタリア語、ポルトガル語。
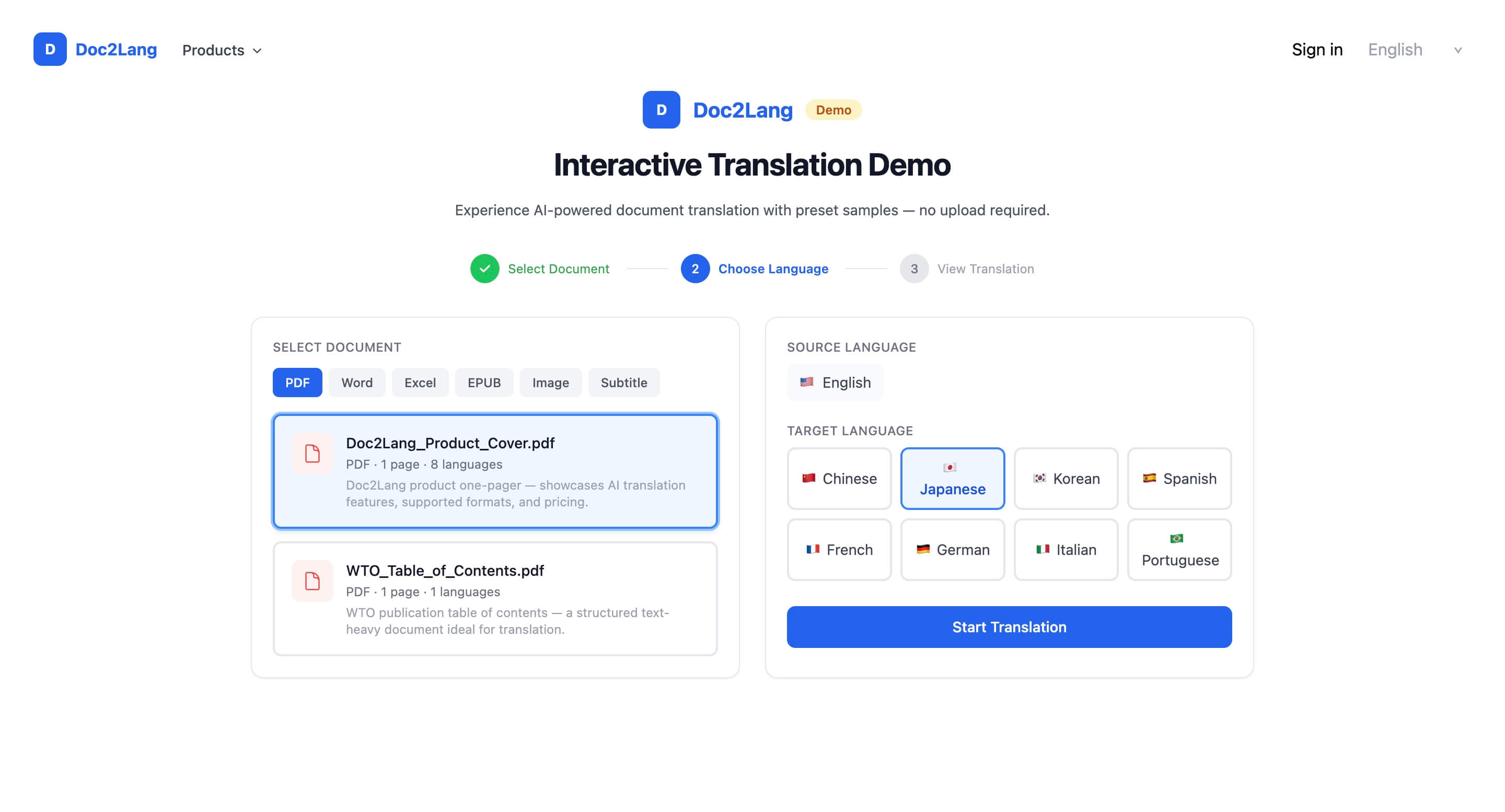
ステップ3:翻訳を表示する。 結果がオリジナルと並んで表示されます。PDFの場合、両側ともズーム・回転・ダウンロードコントロール付きの実際のPDFプレビューとしてレンダリングされます。字幕の場合、両側とも中央カラムにタイムスタンプを配置した同期テーブルとして表示されます。
それだけです。アカウント不要、アップロード不要、キュー待ちもなし。
Doc2Langの字幕翻訳はどうやってタイミングコードを保持するのか
字幕翻訳には独自の技術的な地雷があります。フォーマットは一見単純に見えます。SRTファイルはタイムスタンプと対話行を含むただのプレーンテキストです:
1
00:00:17,000 --> 00:00:19,000
Hello, Mr.Snail!
2
00:00:19,500 --> 00:00:22,000
Aw, you cute little cornu aspersum.しかし、字幕を正しく翻訳するには、いくつかの問題を同時に解決する必要があります:
- タイムスタンプは正確に保持されなければならない。 カンマが1つ欠けていたり改行が間違っていたりするだけで、ファイル全体がVLC、YouTube、Premiere Proで解析に失敗します。
- 行の長さは画面の読み取り速度を尊重しなければならない。 日本語はおおよそ1秒あたり13文字、英語は約17文字です。文字通り翻訳された字幕は、時間内に読めないことがよくあります。
- 文脈は複数行にまたがる。 5行目の「I swear I'm gonna kill her」は、「her」が3行目の誰を指しているか分かって初めて意味が通じます。各行を単独で翻訳するとナンセンスになります。
- 話者のトーンを引き継ぐ必要がある。 キャラクターの声、スラング、個性は翻訳を超えて生き残るべきです。Sprite Frightの「Sugar Buns」を文字通り「砂糖パン」にしてはいけません。
Doc2Langはこれらすべてに対応します。翻訳エンジンは字幕ファイル全体を脚本として読み、シーンをまたいでキャラクターの声を維持し、画面表示時間の制約を尊重し、オリジナルのタイムスタンプを一切触らずにバイト単位で正確なSRTファイルを出力します。
デモでは、BlenderのSprite Frightショートフィルムを使ってご自身で試すことができます。これを選んだのは、クリエイティブ・コモンズでリリースされており(合法的に使用できる)、対話が面白く、ほとんどの字幕翻訳ツールを破綻させるタイトなコメディのタイミングを持っているからです。「Hello, Mr.Snail!」が00:17のちょうどそのタイミングで「やあ、カタツムリさん!」になる様子をご覧ください。同じタイムスタンプ、同じ遊び心のあるトーン。
Doc2LangはSRT、WebVTT、ASS字幕フォーマットに対応し、100以上の言語でタイミングを完全に保持します。
ここまでは字幕ファイルが手元にある場合の話です。動画しかない場合は、動画から字幕を自動生成して翻訳することもできます。
Doc2Langデモを試してみよう
インタラクティブデモは公開中です。サンプルのPDFや字幕ファイルを翻訳してみることがすぐにできます。サインアップなし、アップロードなし、落とし穴なし。
「PDFをオンラインで翻訳」ツールで美しいドキュメントがゴミになって痛い目に遭った経験があるなら、このデモはあなたのためのものです。クリックして色々試してください。日本語翻訳を試したら、次はドイツ語を試してみてください。左右比較ビューを開いてください。翻訳されたPDFをダウンロードして、Adobe Acrobatで開いてみてください。オリジナルと比較してください。すぐに違いが分かると思います。
次に予定していること
現時点でこのデモはPDF翻訳と字幕翻訳をカバーしています。これから数週間のうちに、Doc2Langがサポートするすべてのフォーマットのライブデモを追加していきます:
- Word文書翻訳(DOCX) — スタイル、ヘッダー、フッター、表、埋め込み画像、変更履歴を保持します。特に契約書、レポート、学術論文の翻訳に便利です。
- Excelスプレッドシート翻訳(XLSX、XLSM、CSV) — 数式、条件付き書式、マルチシートブック、ピボットテーブルを保持します。財務モデルやデータエクスポートに不可欠です。
- PowerPointプレゼンテーション翻訳(PPTX) — スライドレイアウト、アニメーション、発表者ノート、埋め込みチャート、SmartArtを保持します。国際的な基調講演や営業デッキに必須です。
- EPUB電子書籍翻訳 — 章の構造、目次、脚注、読み取りフローを保持します。インディー作家が自分の書籍をグローバル市場向けに翻訳するのに使われています。
- 画像翻訳(PNG、JPG、WEBP) — OCRと視覚的な再レンダリングを使用して、画像内テキストのレイアウトを保持します。スクリーンショット、インフォグラフィック、スキャンされたドキュメントの翻訳に便利です。
これらのフォーマットはそれぞれ独自の書式保持の課題を持ち、それぞれが専用のデモを持つ予定です。各デモが公開されたときに通知を受け取るには、リリースノートを購読してください。
よくある質問
Q:Doc2Langデモを使うのにアカウントを作成する必要はありますか?
いいえ。インタラクティブデモはサインアップ不要、アップロード不要、メール認証不要です。完全に事前読み込みされたサンプルドキュメント上で動作します。
Q:Doc2LangのPDF翻訳は何言語に対応していますか?
Doc2LangはPDF翻訳で100以上の言語に対応しています。日本語、中国語(簡体字および繁体字)、韓国語、スペイン語、フランス語、ドイツ語、イタリア語、ポルトガル語、ロシア語、アラビア語、ヒンディー語、ベトナム語、タイ語などが含まれます。
Q:Doc2Langはどの字幕フォーマットに対応していますか?
Doc2LangはSRT、WebVTT、ASS字幕フォーマットに対応しています。すべてのタイミングコード、書式タグ、スタイリングが翻訳中に保持されます。
Q:Doc2LangはスキャンされたPDFを翻訳できますか?
はい。スキャンされた(画像ベースの)PDFの場合、Doc2Langは翻訳前にレイアウトを意識したOCRパスを実行し、その結果を翻訳先言語で完全に検索可能なPDFとして再レンダリングします。
Q:Doc2Langの料金はどのように機能しますか?
Doc2Langは従量課金制を採用しており、サブスクリプションは不要です。支払う前にすべての翻訳を無料でプレビューできるので、満足できる結果にだけお金を払うことができます。
Q:Doc2LangとGoogle TranslateやDeepLの違いは何ですか?
Google TranslateとDeepLは生のテキストの翻訳には優れていますが、ドキュメントの書式を保持しません。Doc2Langはレイアウト保持付きのドキュメント翻訳専用に構築されています。フォント、表、画像、チャート、マルチカラムレイアウトがすべて出力ファイル内でそのまま保たれます。
Doc2LangはAI搭載のドキュメント翻訳プラットフォームで、PDF、Word、Excel、PowerPoint、EPUB、画像、字幕の書式保持翻訳を専門としています。100以上の言語に対応し、従量課金制かつチェックアウト前の無料プレビューを提供しています。インタラクティブデモを試すか、今日ご自身のドキュメントを翻訳してみてください。
関連記事: