인터랙티브 PDF 및 자막 번역기 데모: 서식 보존 번역을 직접 확인해 보세요
회원가입 없이 AI PDF 번역기와 자막 번역기를 사용해 보세요. Doc2Lang이 100개 이상의 언어로 글꼴, 표, 레이아웃, 타이밍 코드를 어떻게 보존하는지 직접 확인해 보세요.
2026년 4월 8일 발행 · 8분 읽기 · Doc2Lang 팀
요약 (TL;DR)
우리는 doc2lang.com에서 인터랙티브 번역 데모를 출시했습니다. 파일 업로드나 회원가입 없이 AI PDF 번역기와 AI 자막 번역기를 테스트해 볼 수 있습니다. 샘플 문서를 선택하고, 100개 이상의 대상 언어 중에서 선택한 다음, 글꼴, 표, 레이아웃, 타이밍 코드가 완벽하게 보존된 번역을 원본과 나란히 확인해 보세요. 이 글에서는 우리가 왜 이 기능을 만들었는지, 서식 보존 문서 번역이 내부적으로 실제로 어떻게 작동하는지, 그리고 앞으로 무엇이 출시될 예정인지 설명합니다.
바로가기:
- 2026년 온라인 PDF 번역의 현주소
- 우리가 인터랙티브 데모를 만든 이유
- Doc2Lang의 PDF 번역이 서식을 보존하는 방법
- 데모 플로우: 세 번의 클릭으로 "와우"까지
- Doc2Lang의 자막 번역이 타이밍 코드를 보존하는 방법
- Doc2Lang 데모 체험하기
- 앞으로의 계획
- 자주 묻는 질문
2026년 온라인 PDF 번역의 현주소
Google에서 "PDF 온라인 번역"을 검색하면 수십 개의 결과가 나옵니다. "PDF 한국어 번역"이나 "SRT 자막 번역"을 검색해도 마찬가지로 수십 개의 결과가 나옵니다. 대부분은 다음과 같이 작동합니다:
- 파일 업로드
- 대기
- 서식이 전혀 없는 평평한 일반 텍스트 덩어리 수신
- Word에서 레이아웃을 재구성하느라 두 시간 허비
이것이 AI 문서 번역의 추한 비밀입니다. 번역 부분은 대부분 해결되었지만, 서식 보존 부분은 그렇지 않습니다. GPT-4나 Claude 같은 대규모 언어 모델은 거의 인간 수준의 정확도로 언어 간 번역을 할 수 있습니다. 어려운 부분은 단어가 아닙니다. 바로 단어를 바꾸는 동안 문서 구조를 그대로 유지하는 것입니다.
일반적인 PDF에는 다음과 같은 요소가 포함됩니다:
- 정확한 x/y 좌표에 배치된 텍스트
- 대상 언어에 대응 폰트가 없을 수도 있는 글꼴
- 보이지 않는 격자선과 정렬된 텍스트 상자로 만들어진 표
- 캡션이 포함된 이미지
- 읽기 순서 메타데이터가 있는 다단 레이아웃
- 머리글, 바닥글, 페이지 번호, 각주
- 벡터 그래픽, 차트, 인라인 수식
단순한 PDF 번역기가 텍스트를 추출하고 번역 API로 보낸 뒤 다시 붙여 넣으면, 이 모든 구조가 사라져 버립니다. 더 나쁜 건, 번역된 텍스트는 거의 항상 원문과 길이가 다르다는 점입니다. 일본어는 영어의 약 60% 길이이고, 한국어도 대체로 영어보다 짧으며, 독일어는 약 130%입니다. 그래서 좌표를 그대로 보존해도 텍스트가 넘치거나 공백이 생깁니다.
이것이 Doc2Lang이 지난 2년 동안 해결해 온 문제입니다. 그리고 방금 출시한 데모는 방문자들이 아무것도 약속할 필요 없이 실시간으로 이 해결책이 작동하는 모습을 볼 수 있는 첫 번째 기회입니다.
우리가 인터랙티브 데모를 만든 이유 (그리고 당신도 만들어야 하는 이유)
Doc2Lang의 기존 랜딩 페이지는 다음과 같았습니다:
깔끔하고, 기능적이며, 해야 할 일을 정확하게 알려 주었습니다. 그러나 분석 데이터는 냉혹한 이야기를 들려주었습니다. 대부분의 방문자는 15초 이내에 떠났습니다. 남은 사람들은 업로드 단계에서 종종 이탈했습니다. 업로드를 완료한 소수의 사람들은 잘 전환되었지만, 그 위의 퍼널은 곳곳에서 새고 있었습니다.
우리는 사용자들과 대화했습니다. 피드백은 일관되었습니다:
이번 달에 다른 PDF 번역기 다섯 개를 시도해 봤어요. 모두 서식 보존을 약속했지만, 어느 것도 지키지 못했습니다. 왜 또 다른 파일을 당신들에게 낭비해야 하나요?
타당한 이야기입니다. 이 분야의 신뢰는 무너져 있었고, 우리는 카피로 그것을 고칠 수 없었습니다. 그래서 시작하는 데 아무런 신뢰가 필요 없는 경험을 만들었습니다. 바로 인터랙티브 번역 데모입니다.
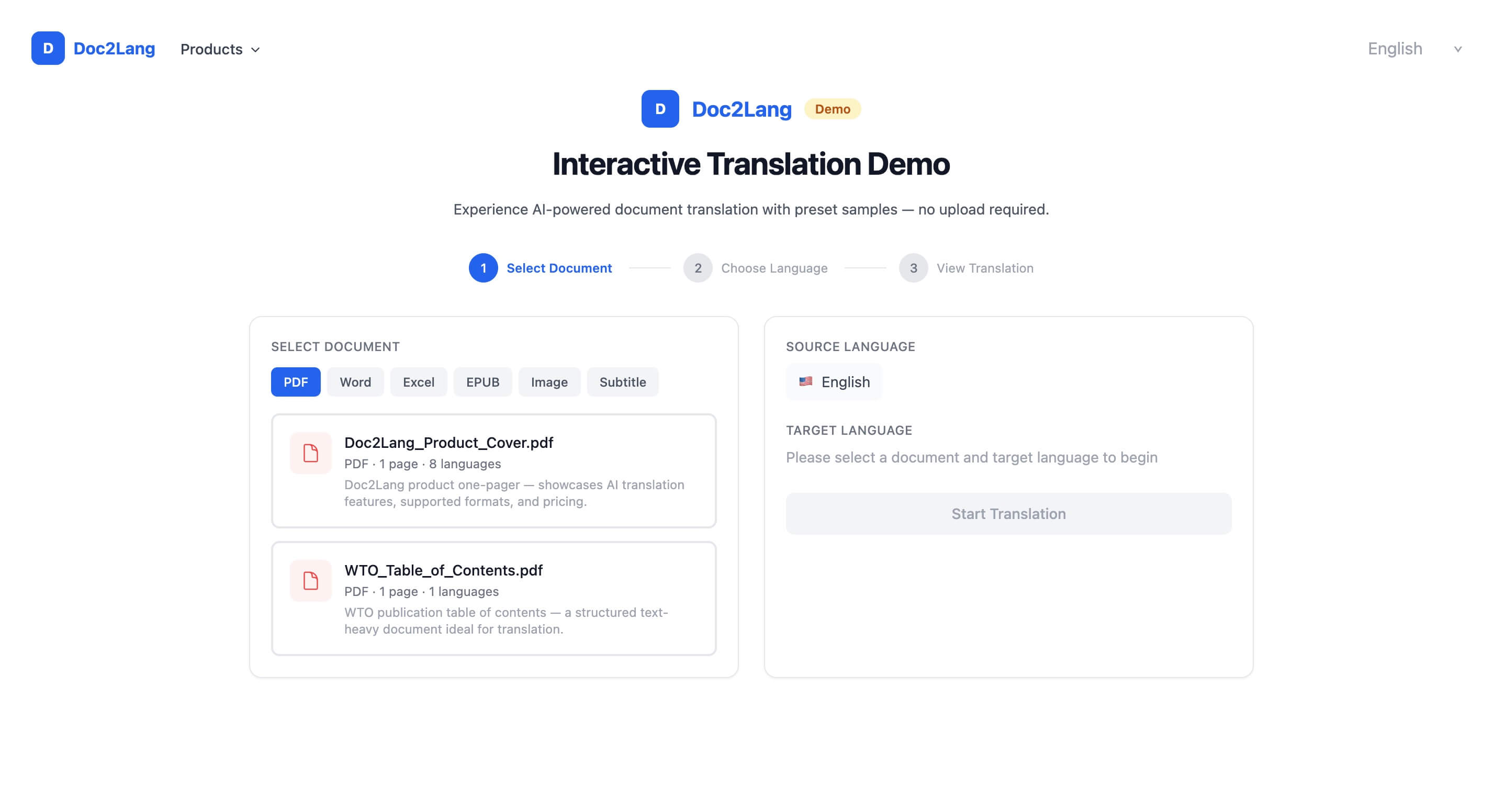
원칙은 간단합니다. 사람들에게 무언가를 요구하기 전에 먼저 제품을 경험하게 하는 것입니다. 회원가입도, 업로드도, 이메일 인증도 없습니다. 미리 로드된 샘플 문서, 세 번의 클릭, 즉각적인 결과.
Doc2Lang의 PDF 번역이 서식을 보존하는 방법
잠시 기술적인 이야기를 해 보겠습니다. 이 부분은 대부분의 블로그 글이 얼버무리는 부분이기 때문입니다.
Doc2Lang이 번역을 위해 PDF를 처리할 때, 단순히 텍스트를 추출해서 번역하는 것이 아닙니다. 다단계 파이프라인을 실행합니다:
1단계: 문서 파싱
PDF를 텍스트 블록, 표, 이미지, 벡터 그래픽 등 레이아웃 요소의 구조화된 트리로 파싱하며, 각 요소의 위치, 크기, 글꼴, 색상, z-인덱스가 보존됩니다. 이것은 OCR이 아닙니다. 네이티브 PDF의 경우 실제 문서 구조를 읽습니다. 스캔된 PDF의 경우 레이아웃 인식 OCR 패스로 대체합니다.
2단계: 의미론적 그룹화
함께 속한 인접 텍스트 블록(예: 두 개의 단에 걸쳐 분할된 단락, 또는 제목과 부제목)은 의미론적으로 그룹화됩니다. 이것이 중요한 이유는 각 블록을 고립된 상태로 번역하면 엉망이 되기 때문입니다. 맥락이 모든 것입니다.
3단계: 레이아웃 제약이 있는 번역
각 의미론적 그룹은 명시적인 제약 조건과 함께 LLM에 의해 번역됩니다: "이 단락을 한국어로 번역하되, 결과는 이 글꼴을 사용해 이 정도 너비의 상자에 맞아야 합니다." 모델은 사용 가능한 공간에 맞는 표현을 선택하도록 지시받습니다. 제목의 경우 종종 더 짧은 동의어를 고르는 것을 의미합니다. 본문의 경우 문장을 재구성하는 것을 의미할 수 있습니다.
4단계: 글꼴 대체
원본 PDF가 대상 언어의 문자 집합을 지원하지 않는 글꼴을 사용하는 경우(예: 일본어나 중국어를 렌더링해야 하는 라틴 전용 글꼴), 지원 가능한 가장 시각적으로 유사한 글꼴로 대체합니다. 그래서 Doc2Lang의 번역은 기본 시스템 글꼴처럼 보이지 않습니다. 대상 언어가 무엇이든, 우리는 원본과의 시각적 연속성을 유지합니다.
5단계: 재렌더링
마지막으로, 번역된 텍스트, 원본 이미지, 원본 벡터 그래픽, 그리고 조정된 레이아웃 상자를 사용해 PDF를 처음부터 다시 렌더링합니다. 결과물은 Adobe Acrobat에서 열 수 있는 실제 PDF 파일이며, 스크린샷이 아닙니다.
데모에서 직접 결과를 확인할 수 있습니다:
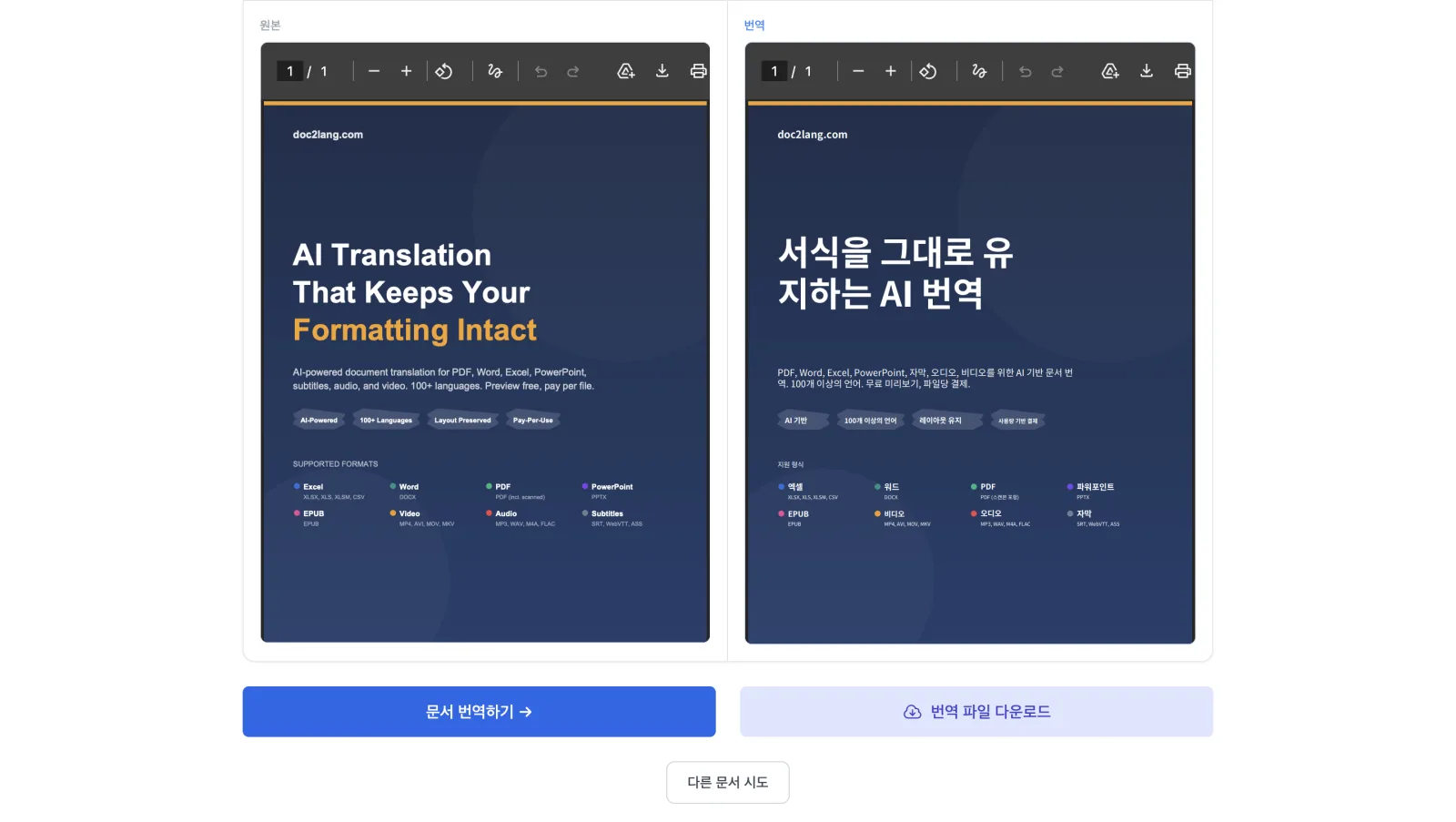
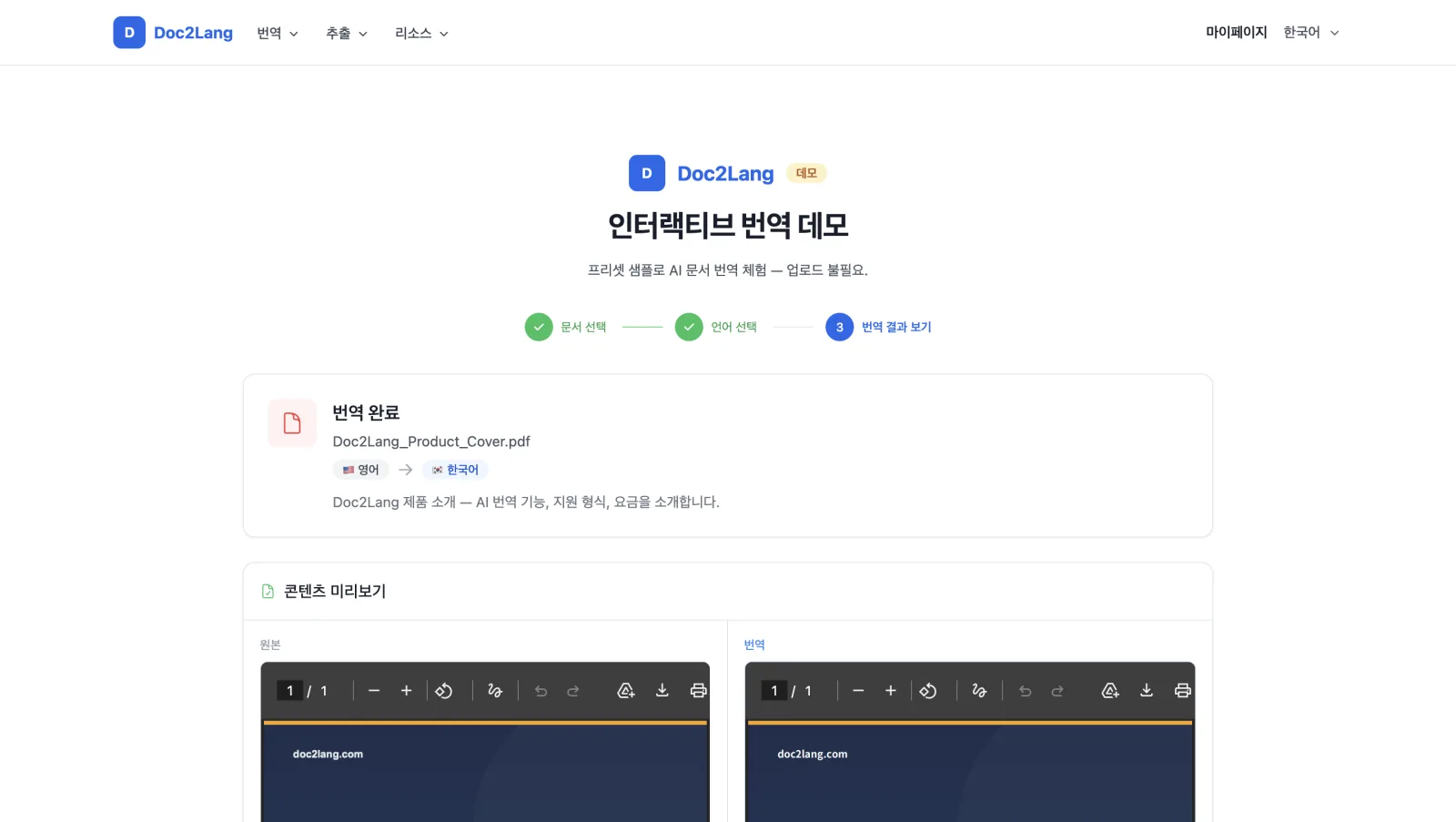
왼쪽의 영어 버전에는 어두운 남색 히어로 섹션, "Formatting Intact"에 있는 오렌지색 액센트, 네 개의 기능 뱃지, 그리고 컬러 글머리 기호가 있는 지원 형식 그리드가 있습니다. 오른쪽의 한국어 버전에는 모든 요소가 같은 위치에 그대로 있습니다. 바뀐 것은 오직 언어뿐입니다. 제목은 이제 "서식을 그대로 유지하는 AI 번역"이라고 표시되고, 네 개의 기능 뱃지는 "AI 기반", "100개 이상의 언어", "레이아웃 유지", "사용량 기반 결제"로 바뀌었으며, 지원 형식 그리드의 글머리 기호 색상도 원본과 그대로 일치합니다. 같은 디자인, 다른 언어.
이것이 실제로 서식 보존 PDF 번역이 의미하는 바입니다. "최선을 다했습니다"가 아니라, 실제로 동일한 것입니다. 데모에서는 똑같은 한국어 비교를 세 번의 클릭만으로 직접 만들어 볼 수 있습니다.
데모 플로우: 세 번의 클릭으로 "와우"까지
우리는 의도적으로 데모를 양식의 반대가 되도록 설계했습니다. 세 단계, 마찰 없음:
1단계: 샘플 문서 선택. 복잡한 레이아웃의 제품 원 페이지(Doc2Lang_Product_Cover.pdf), 구조화된 텍스트 중심의 WTO 출판물 목차(WTO_Table_of_Contents.pdf), 그리고 Blender 오픈 무비 자막 파일(Sprite Fright.srt) 등, 실제 환경의 문제들을 보여주는 파일을 미리 로드해 두었습니다. 이것들은 장난감 같은 예제가 아니라 진짜 엣지 케이스입니다.
2단계: 대상 언어 선택. 우리는 PDF 번역과 자막 번역 모두 100개 이상의 언어를 지원합니다. 데모에서는 가장 인기 있는 8개 언어를 국기 이모지와 함께 클릭 가능한 버튼으로 노출합니다: 중국어, 일본어, 한국어, 스페인어, 프랑스어, 독일어, 이탈리아어, 포르투갈어.
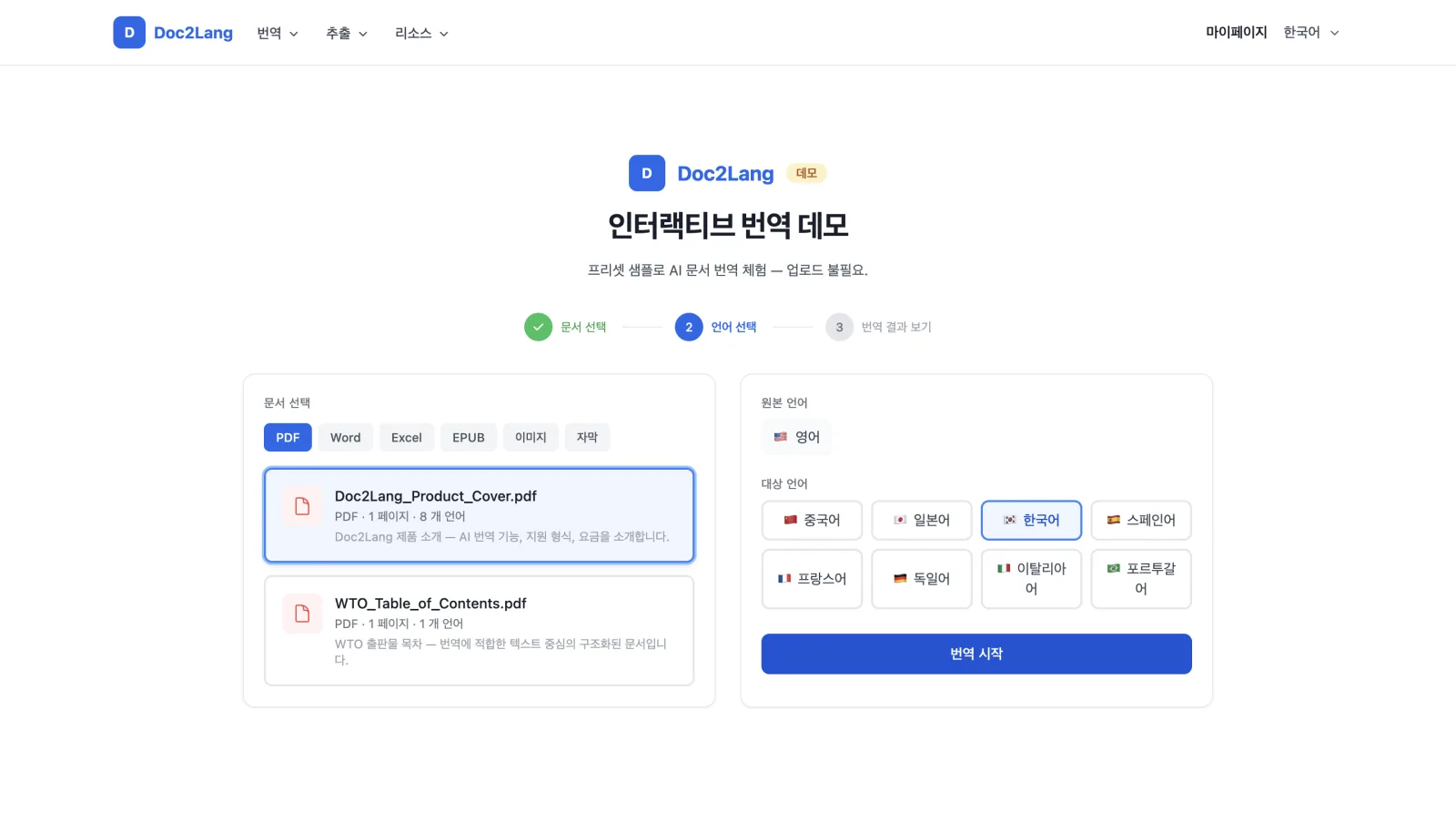
3단계: 번역 보기. 결과는 원본과 나란히 로드됩니다. PDF의 경우 양쪽 모두 확대, 회전, 다운로드 컨트롤이 있는 실제 PDF 미리보기로 렌더링됩니다. 자막의 경우 양쪽 모두 중앙 열에 타임스탬프가 있는 동기화된 표로 표시됩니다.
그게 전부입니다. 계정도, 업로드도, 대기열 기다림도 없습니다.
Doc2Lang의 자막 번역이 타이밍 코드를 보존하는 방법
자막 번역에는 자체적인 기술적 지뢰가 있습니다. 포맷은 겉보기에는 간단해 보입니다. SRT 파일은 타임스탬프와 대사 줄이 있는 일반 텍스트일 뿐입니다:
1
00:00:17,000 --> 00:00:19,000
Hello, Mr.Snail!
2
00:00:19,500 --> 00:00:22,000
Aw, you cute little cornu aspersum.그러나 자막을 올바르게 번역하려면 여러 문제를 동시에 해결해야 합니다:
- 타임스탬프는 정확히 보존되어야 합니다. 쉼표 하나가 빠지거나 줄 바꿈이 잘못되면 VLC, YouTube, Premiere Pro에서 전체 파일 파싱이 실패합니다.
- 줄 길이는 화면 읽기 속도를 존중해야 합니다. 일본어는 초당 약 13자가 들어가고, 영어는 약 17자가 들어갑니다. 문자 그대로 번역된 자막은 종종 제시간에 읽을 수 없습니다.
- 맥락은 여러 줄에 걸쳐 있습니다. 5번째 줄의 "I swear I'm gonna kill her"는 3번째 줄에서 "her"가 누구를 가리키는지 알아야만 의미가 통합니다. 각 줄을 고립된 상태로 번역하면 말도 안 되는 결과가 나옵니다.
- 화자의 어조가 전달되어야 합니다. 캐릭터의 목소리, 속어, 성격이 번역에도 살아남아야 합니다. Sprite Fright의 "Sugar Buns"가 문자 그대로 "설탕 빵"이 되어서는 안 됩니다. 데모에서는 캐릭터의 장난스러운 별명을 살려 "슈거 번스"로 옮깁니다.
Doc2Lang은 이 모든 것을 처리합니다. 번역 엔진은 전체 자막 파일을 대본처럼 읽고, 장면 간에 캐릭터 목소리를 유지하며, 화면 시간 제약을 존중하고, 원본 타임스탬프가 손대지 않은 바이트 단위로 완벽한 SRT 파일을 출력합니다.
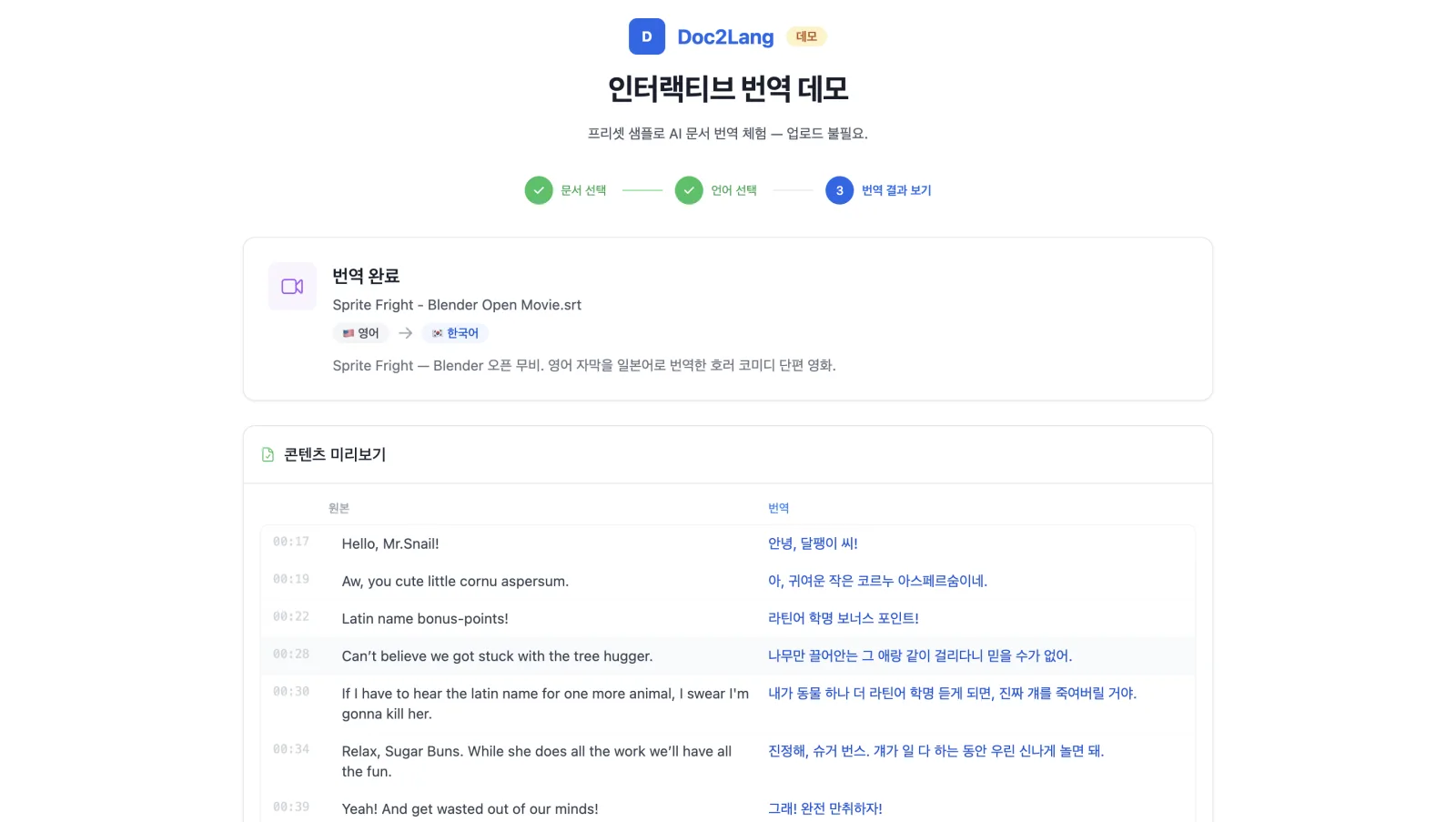
Blender의 Sprite Fright 단편 영화로 데모에서 직접 시도해 볼 수 있습니다. 우리가 이 영화를 선택한 이유는 크리에이티브 커먼즈로 공개되어 있고(그래서 합법적으로 사용할 수 있으며), 대사가 재미있고, 대부분의 자막 번역기를 깨뜨리는 빡빡한 코미디 타이밍이 있기 때문입니다. "Hello, Mr.Snail!"이 정확히 00:17에 어떻게 "안녕, 달팽이 씨!"로 바뀌는지 지켜보세요. 같은 타임스탬프, 같은 장난스러운 어조입니다.
Doc2Lang은 100개 이상의 언어에 걸쳐 완전한 타이밍 보존과 함께 SRT, WebVTT, ASS 자막 형식을 지원합니다.
여기까지는 자막 파일이 이미 있는 경우입니다. 영상만 있다면 Doc2Lang이 영상에서 자막을 자동 생성하고 번역하는 것까지 한 번에 처리합니다.
Doc2Lang 데모 체험하기
인터랙티브 데모는 지금 이용할 수 있습니다. 바로 샘플 PDF나 자막 파일을 번역해 보기를 눌러 보세요. 회원가입도, 업로드도, 숨은 조건도 없습니다.
아름다운 문서를 엉망으로 만들어 버리는 "PDF 온라인 번역" 도구에 데인 적이 있다면, 이 데모는 당신을 위한 것입니다. 마음껏 클릭해 보세요. 한국어 번역을 해 본 다음 일본어 번역도 해 보세요. 나란히 보기를 열어 보세요. 번역된 PDF를 다운로드해서 Adobe Acrobat으로 열어 보세요. 원본과 비교해 보세요. 우리는 당신이 차이를 즉시 알아볼 것이라고 생각합니다.
앞으로의 계획
현재 데모는 PDF 번역과 자막 번역을 다룹니다. 앞으로 몇 주에 걸쳐 Doc2Lang이 지원하는 모든 형식에 대한 라이브 데모를 추가할 예정입니다:
- Word 문서 번역 (DOCX) — 스타일, 머리글, 바닥글, 표, 포함된 이미지, 변경 내용 추적을 보존합니다. 계약서, 보고서, 학술 논문 번역에 특히 유용합니다.
- Excel 스프레드시트 번역 (XLSX, XLSM, CSV) — 수식, 조건부 서식, 다중 시트 워크북, 피벗 테이블을 보존합니다. 재무 모델과 데이터 내보내기에 필수적입니다.
- PowerPoint 프레젠테이션 번역 (PPTX) — 슬라이드 레이아웃, 애니메이션, 발표자 메모, 포함된 차트, SmartArt를 보존합니다. 국제 기조연설과 영업 자료에 필수적입니다.
- EPUB 전자책 번역 — 장 구조, 목차, 각주, 읽기 흐름을 보존합니다. 글로벌 시장을 위해 책을 번역하는 독립 작가들이 사용합니다.
- 이미지 번역 (PNG, JPG, WEBP) — OCR과 시각적 재렌더링을 사용해 이미지 내 텍스트 레이아웃을 보존합니다. 스크린샷, 인포그래픽, 스캔된 문서 번역에 유용합니다.
이러한 각 형식은 고유한 서식 보존 과제를 가지고 있으며, 각각 전용 데모가 제공될 예정입니다. 각 데모가 출시될 때 알림을 받으려면 릴리스 노트를 구독하세요.
자주 묻는 질문
Q: Doc2Lang 데모를 사용하려면 계정을 만들어야 하나요?
아니요. 인터랙티브 데모는 회원가입, 업로드, 이메일 인증이 전혀 필요 없습니다. 전적으로 미리 로드된 샘플 문서에서 실행됩니다.
Q: Doc2Lang의 PDF 번역기는 몇 개의 언어를 지원하나요?
Doc2Lang은 PDF 번역에 대해 한국어, 영어, 일본어, 중국어(간체 및 번체), 스페인어, 프랑스어, 독일어, 이탈리아어, 포르투갈어, 러시아어, 아랍어, 힌디어, 베트남어, 태국어를 비롯해 100개 이상의 언어를 지원합니다.
Q: Doc2Lang은 어떤 자막 형식을 지원하나요?
Doc2Lang은 SRT, WebVTT, ASS 자막 형식을 지원합니다. 모든 타이밍 코드, 서식 태그, 스타일이 번역 중에 보존됩니다.
Q: Doc2Lang은 스캔된 PDF도 번역할 수 있나요?
네. 스캔된(이미지 기반) PDF의 경우, Doc2Lang은 번역 전에 레이아웃 인식 OCR 패스를 실행한 다음, 대상 언어로 완전히 검색 가능한 PDF로 결과를 다시 렌더링합니다.
Q: Doc2Lang의 요금은 어떻게 작동하나요?
Doc2Lang은 파일별 과금 방식을 사용합니다. 구독은 필요 없습니다. 결제 전에 모든 번역을 무료로 미리 볼 수 있으므로, 만족스러운 결과에 대해서만 비용을 지불합니다.
Q: Doc2Lang과 Google Translate 또는 DeepL의 차이점은 무엇인가요?
Google Translate와 DeepL은 원시 텍스트 번역에는 훌륭하지만, 문서 서식을 보존하지 않습니다. Doc2Lang은 레이아웃 보존을 갖춘 문서 번역을 위해 특별히 만들어졌습니다. 글꼴, 표, 이미지, 차트, 다단 레이아웃이 모두 출력 파일에서 그대로 유지됩니다.
Doc2Lang은 PDF, Word, Excel, PowerPoint, EPUB, 이미지, 자막에 대한 서식 보존 번역을 전문으로 하는 AI 기반 문서 번역 플랫폼입니다. 100개 이상의 언어를 지원하며, 파일별 과금과 결제 전 무료 미리보기를 제공합니다. 인터랙티브 데모 체험하기 또는 지금 직접 문서를 번역해 보세요.
관련 글: