交互式 PDF 与字幕翻译演示:亲眼见证保留格式的翻译效果
无需注册即可试用我们的 AI PDF 翻译器和字幕翻译器,并通过真实样例检查字体、表格、排版和时间码的保留效果。
发布于 2026 年 4 月 8 日 · 8 分钟阅读 · Doc2Lang 团队
内容摘要
我们在 doc2lang.com 推出了一个交互式翻译演示,您无需上传任何内容、无需注册即可测试我们的 AI PDF 翻译器和 AI 字幕翻译器。选择一份示例文档,从 100 多种目标语言中任选其一,然后与原文并排检查字体、表格、排版和时间码在实际样例中的保留效果。本文将解释我们为什么要构建它、保留格式的文档翻译背后的实现原理,以及接下来会有哪些新功能。
跳转到:
- 2026 年在线 PDF 翻译的现状
- 我们为什么构建交互式演示
- Doc2Lang 的 PDF 翻译如何保留格式
- 演示流程:三次点击带来的惊艳
- Doc2Lang 的字幕翻译如何保留时间码
- 试用 Doc2Lang 演示
- 接下来会有什么
- 常见问题
2026 年在线 PDF 翻译的现状
在 Google 上搜索"translate PDF online",您会得到几十个结果。搜索"PDF 翻译成中文"或"SRT 字幕翻译",又会得到更多结果。其中大多数的工作流程是这样的:
- 上传文件
- 等待
- 收到一堆毫无格式的扁平化纯文本
- 花两个小时在 Word 里重建排版
这是 AI 文档翻译行业不愿提及的秘密:翻译本身基本上已经被攻克,但格式保留却没有。像 GPT-4 和 Claude 这样的大型语言模型,已经可以在各种语言之间以接近人类的准确度进行翻译。难点不在于词语——而在于替换词语时如何保持文档结构完整。
一份典型的 PDF 包含:
- 位于精确 x/y 坐标上的文本
- 在目标语言中可能没有对应版本的字体
- 由隐藏的网格线和对齐的文本框构建的表格
- 带有嵌入式说明文字的图像
- 带有阅读顺序元数据的多栏布局
- 页眉、页脚、页码、脚注
- 矢量图形、图表和内嵌数学公式
当一个简单粗暴的 PDF 翻译器提取文本、发送给翻译 API、再拼接回来时,所有这些结构都会丢失。更糟糕的是,译文的长度几乎总是与原文不同——中文通常只有英语字符数的一半左右,而德语大约是英语的 130%——所以即使保留了坐标,文本也会溢出或留下空隙。
这就是 Doc2Lang 过去两年一直在解决的问题。而我们刚刚推出的演示,是访客第一次可以在不做任何承诺的情况下,实时看到解决方案的运行效果。
我们为什么构建交互式演示(以及您为什么也应该这样做)
Doc2Lang 的旧版首页是这样的:
简洁。实用。清楚地告诉你该做什么。然而,我们的分析数据讲述了一个残酷的故事:大多数访客会在 15 秒内离开。留下来的人通常在上传环节就流失了。少数完成上传的访客转化率很高——但漏斗的上游到处都在漏水。
我们与用户交流。反馈非常一致:
我这个月试用了其他五款 PDF 翻译器。它们都承诺保留格式。没有一款做到。我为什么要在你们身上再浪费一份文件?
有道理。这个品类的信任已经破裂,我们无法仅靠文案来修复。所以我们打造了一种零信任门槛的体验:交互式翻译演示。
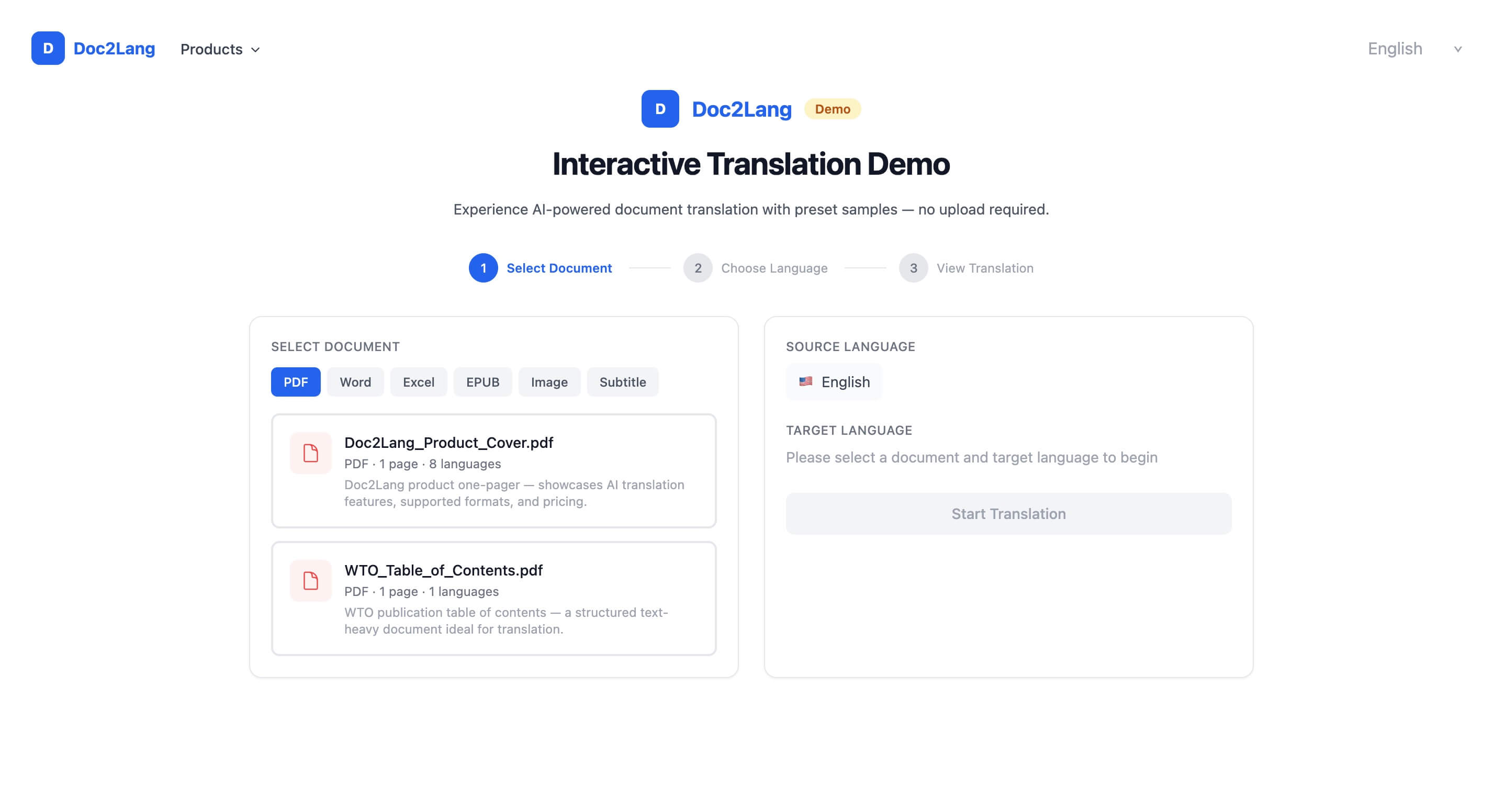
原则很简单:让人们在向他们索要任何东西之前,先体验产品。无需注册,无需上传,无需邮箱验证。预加载的示例文档,三次点击,即时呈现结果。
Doc2Lang 的 PDF 翻译如何保留格式
让我们来稍微深入技术层面,因为这是大多数博客文章都一带而过的部分。
当 Doc2Lang 处理一份 PDF 进行翻译时,它不仅仅是提取文本然后翻译,而是运行一个多阶段的流水线:
阶段一:文档解析
我们将 PDF 解析为一棵结构化的布局元素树——文本块、表格、图像、矢量图形——每个元素都保留其位置、大小、字体、颜色和 z-index。这不是 OCR;对于原生 PDF,我们直接读取真实的文档结构。对于扫描版 PDF,我们会退而使用具备布局感知能力的 OCR 流程。
阶段二:语义分组
属于同一整体的相邻文本块(例如跨两栏分割的段落,或标题与其副标题)会被进行语义分组。这一点很重要,因为单独翻译每个文本块会产生垃圾结果——上下文就是一切。
阶段三:带有布局约束的翻译
每个语义组由 LLM 进行翻译,并附带明确的约束:"将这段文字翻译成中文,但结果必须容纳在这个字体下宽度为特定像素数的方框内。"模型被指示选择能适应可用空间的措辞。对于标题,这通常意味着挑选更短的同义词。对于正文,则可能意味着重新组织句子。
阶段四:字体替换
如果原始 PDF 使用的字体不支持目标语言的字符集(例如,要求一个只支持拉丁字母的字体渲染中文),我们会用视觉上最接近、且支持该字符集的字体来替代。这就是为什么 Doc2Lang 的译文看起来不像默认系统字体——无论目标语言是什么,我们都与原文保持了视觉上的连续性。
阶段五:重新渲染
最后,我们使用翻译后的文本、原始图像、原始矢量图形以及调整后的布局框,从头开始重新渲染 PDF。输出的是一份可以在 Adobe Acrobat 中打开的真正 PDF 文件,而不是它的截图。
您可以在演示中亲眼见证效果:
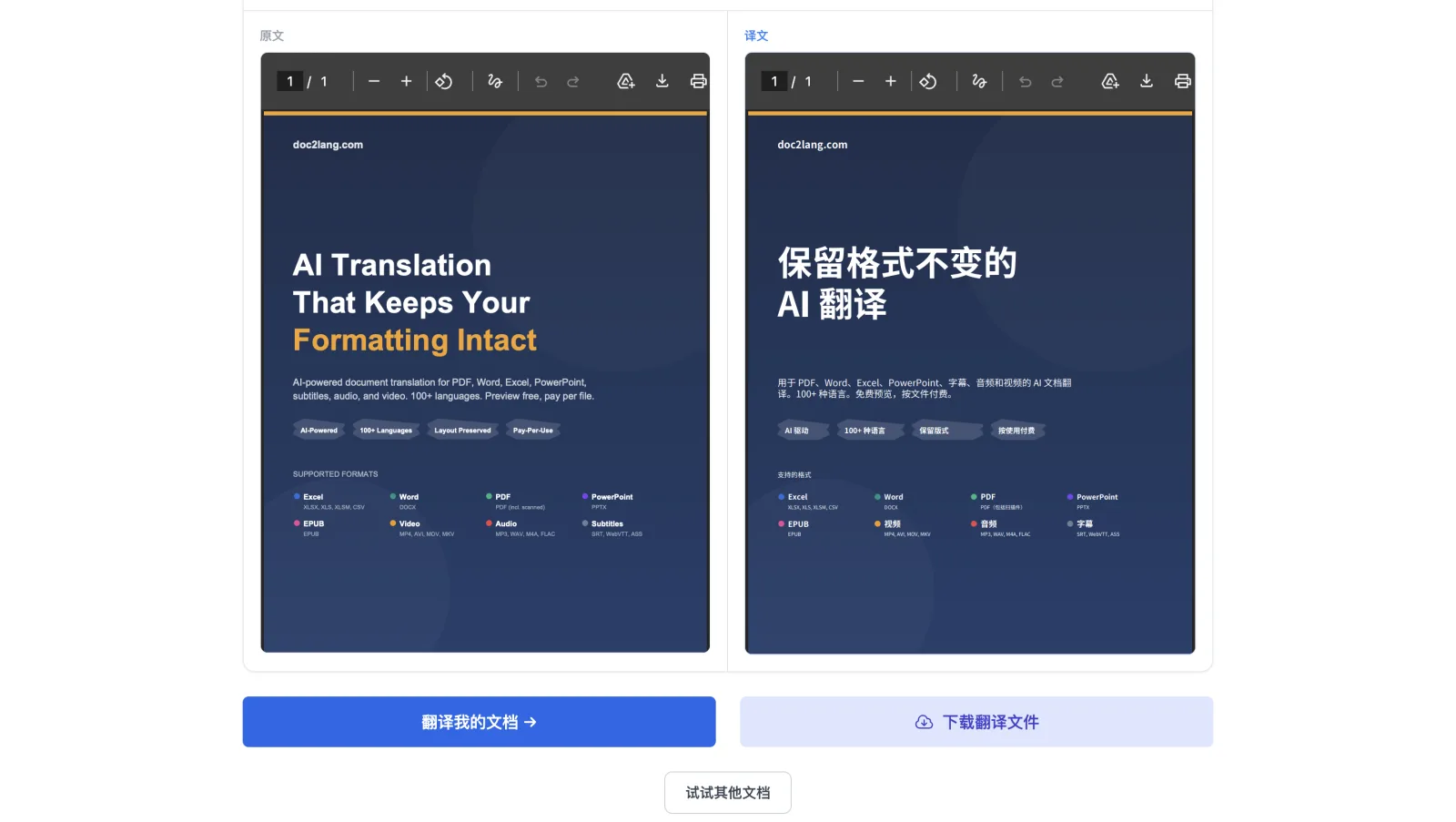
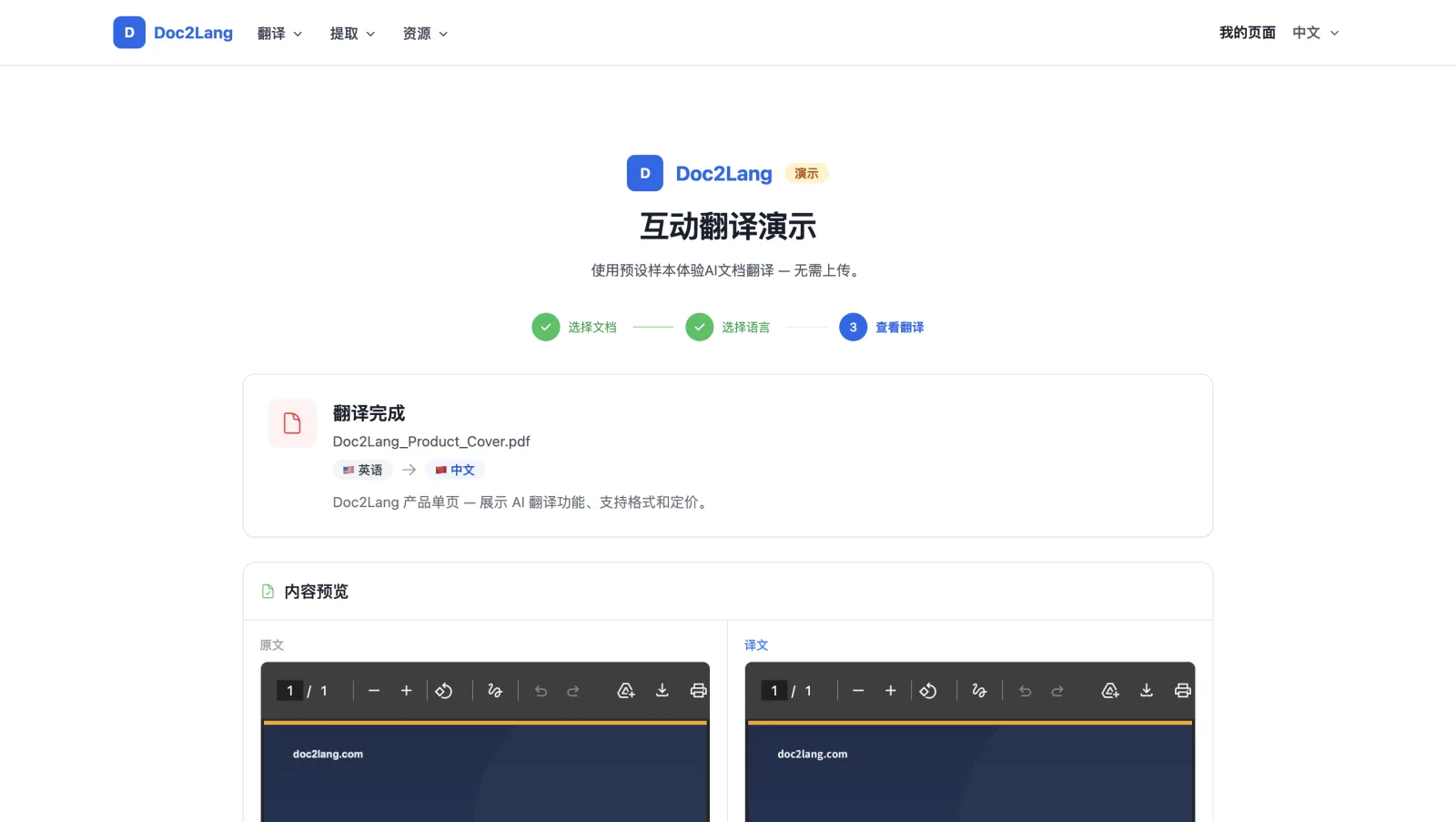
左侧英文版包含深藏青色主视觉区块、橙色强调文字、四个特性标签和带彩色项目符号的格式网格。右侧中文版保留了这些主要视觉结构,并根据中文长度重新排版;主标题变成了"保留格式不变的 AI 翻译",四个特性标签显示为"AI 驱动"、"100+ 种语言"、"保留版式"、"按使用付费"。
这就是保留格式的 PDF 翻译在实际样例中的含义:主要视觉元素仍在原来的位置,译文则根据中文长度重新排版。不同 PDF 的字体、内部结构和文字长度不同,实际结果也会有所差异;你可以在演示里直接下载这个中文版进行检查。
演示流程:三次点击带来的惊艳
我们特意将演示设计成表单的对立面。三个步骤,毫无阻力:
第一步:选择一份示例文档。 我们预加载了能够展现真实世界挑战的文件——一份具有复杂排版的产品单页(Doc2Lang_Product_Cover.pdf)、一份结构化且文字密集的 WTO 出版物目录(WTO_Table_of_Contents.pdf),以及一份 Blender 开源电影字幕文件(Sprite Fright.srt)。这些都是真实的边界案例,而不是简单的玩具示例。
第二步:选择目标语言。 我们支持 100 多种语言用于 PDF 翻译和字幕翻译。演示将八种最受欢迎的语言作为可点击按钮呈现,并带有国旗表情符号:中文、日语、韩语、西班牙语、法语、德语、意大利语和葡萄牙语。
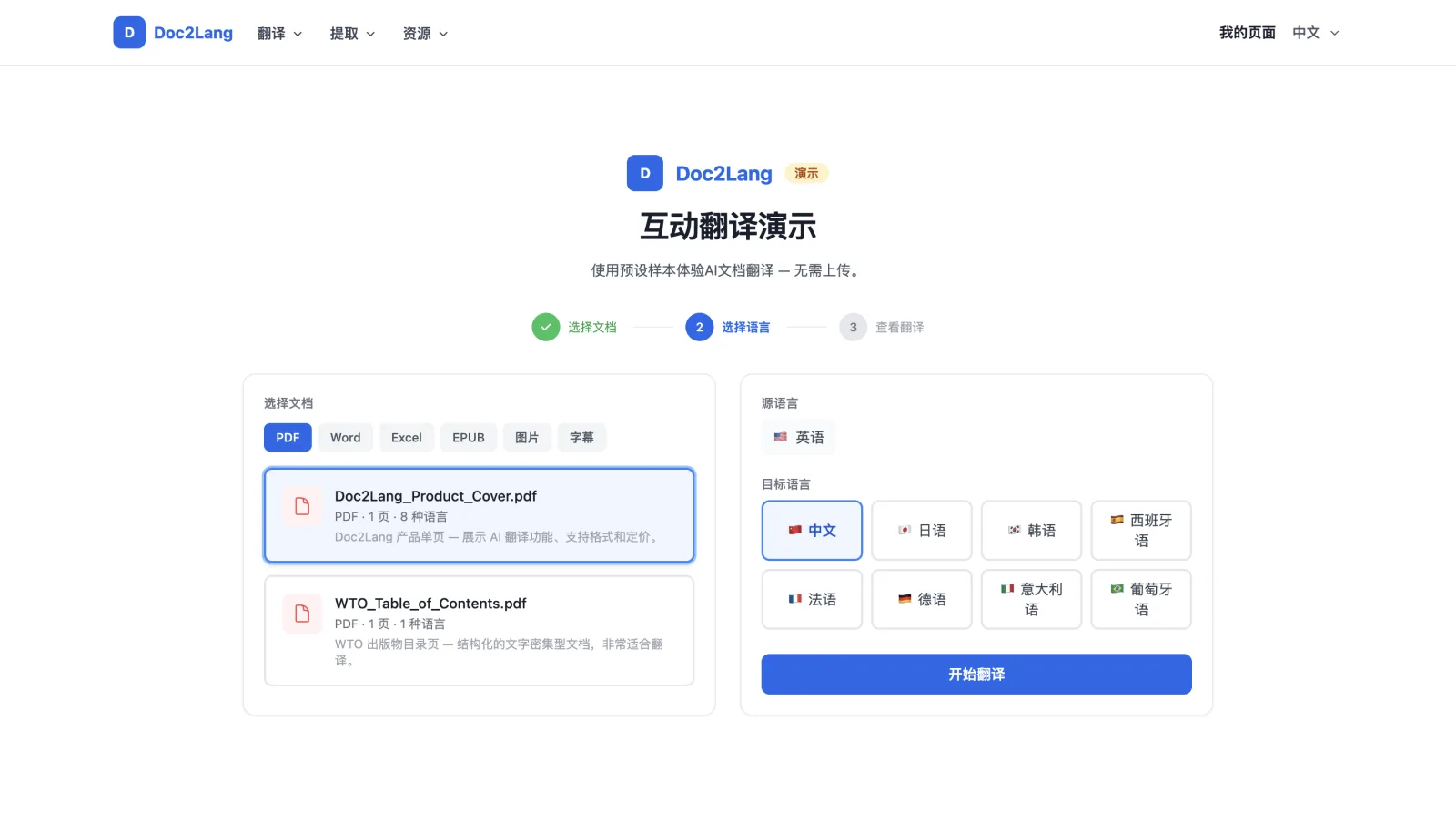
第三步:查看译文。 结果会与原文并排加载。对于 PDF,两侧都以实际的 PDF 预览形式渲染,配有缩放、旋转和下载控件。对于字幕,两侧以同步表格形式呈现,中间列显示时间戳。
就是这样。无需账户,无需上传,无需排队等待。
Doc2Lang 的字幕翻译如何保留时间码
字幕翻译有它自己的技术雷区。这种格式看起来似乎简单得具有欺骗性——SRT 文件只是带有时间戳和对白行的纯文本:
1
00:00:17,000 --> 00:00:19,000
Hello, Mr.Snail!
2
00:00:19,500 --> 00:00:22,000
Aw, you cute little cornu aspersum.但是正确地翻译字幕需要同时解决多个问题:
- 时间戳必须精确保留。 缺少一个逗号或错误的换行符,整个文件就无法在 VLC、YouTube 或 Premiere Pro 中解析。
- 行长度必须符合屏幕阅读速度。 日语每秒约可容纳 13 个字符;英语约为 17 个字符。一条字面翻译的字幕往往无法在规定时间内被看完。
- 上下文跨越多行。 第 5 行的"I swear I'm gonna kill her"只有在你知道第 3 行中"her"指的是谁时才有意义。孤立地翻译每一行会产生毫无逻辑的结果。
- 说话人的语气必须传达出来。 角色的声音、俚语和个性应该在翻译中得以保留。Sprite Fright 中的"Sugar Buns"不应被生硬地直译成"糖面包"——在演示里,它被译成了自然的"甜心"。
Doc2Lang 会把整个字幕文件当作剧本读取,在各个场景中保持角色语气,遵守屏幕显示时长的约束,并输出保留原始时间戳、可正常解析的 SRT 文件。
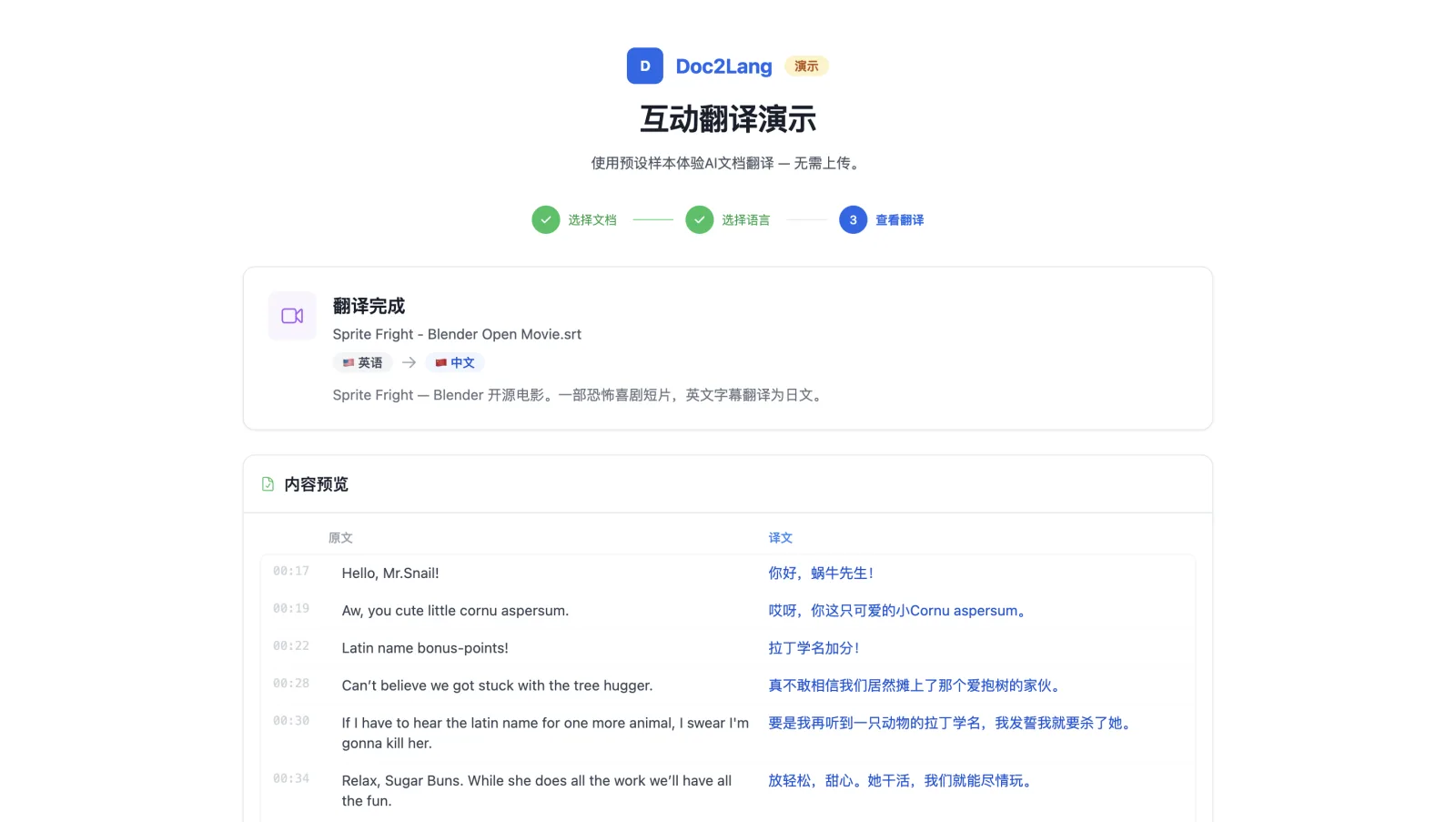
您可以在演示中使用 Blender 的 Sprite Fright 短片亲自尝试。我们选择它是因为它是以 Creative Commons 许可发布的(所以我们可以合法使用),对白幽默,并且拥有紧凑的喜剧时间节奏,这会让大多数字幕翻译器都失效。看看"Hello, Mr.Snail!"如何在 00:17 变成"你好,蜗牛先生!"——相同的时间戳,相同俏皮的语气。
Doc2Lang 支持 SRT、WebVTT 和 ASS 字幕格式,在 100 多种语言之间完整保留时间信息。
以上说的都是你已经有字幕文件的情况。如果手上只有视频,Doc2Lang 也可以从视频里自动生成字幕并翻译,一次跑完。
试用 Doc2Lang 演示
交互式演示现已上线,你可以直接试翻一个示例 PDF 或字幕文件。无需注册,无需上传,没有套路。
如果您曾经被某个"在线翻译 PDF"工具坑过、让它把您精美的文档压扁成一堆垃圾,那么这个演示就是为您准备的。随意点击。试试中文翻译,再试试德文翻译。打开并排对比视图。下载翻译后的 PDF,用 Adobe Acrobat 打开。与原文进行对比。我们相信您会立即看出差别。
接下来会有什么
目前演示涵盖了 PDF 翻译和字幕翻译。在接下来的几周里,我们将为 Doc2Lang 支持的每种格式添加实时演示:
- Word 文档翻译(DOCX)——保留样式、页眉、页脚、表格、嵌入图像和修订记录。对翻译合同、报告和学术论文尤其有用。
- Excel 电子表格翻译(XLSX、XLSM、CSV)——保留公式、条件格式、多工作表簿和数据透视表。对财务模型和数据导出至关重要。
- PowerPoint 演示文稿翻译(PPTX)——保留幻灯片版式、动画、演讲者备注、嵌入图表和 SmartArt。对国际主题演讲和销售演示至关重要。
- EPUB 电子书翻译——保留章节结构、目录、脚注和阅读流。独立作者用它来为全球市场翻译自己的书籍。
- 图像翻译(PNG、JPG、WEBP)——使用 OCR 加视觉重新渲染来保留图像内文本的布局。对翻译屏幕截图、信息图和扫描文档很有用。
这些格式每一种都有自己独特的格式保留挑战,每一种都将拥有专属的演示。订阅我们的发布说明,以便在每个演示上线时收到通知。
常见问题
问:使用 Doc2Lang 演示需要创建账户吗?
不需要。交互式演示零注册、零上传、零邮箱验证。它完全运行在预加载的示例文档之上。
问:Doc2Lang 的 PDF 翻译器支持多少种语言?
Doc2Lang 支持超过 100 种语言的 PDF 翻译,包括中文(简体和繁体)、英语、日语、韩语、西班牙语、法语、德语、意大利语、葡萄牙语、俄语、阿拉伯语、印地语、越南语、泰语等等。
问:Doc2Lang 支持哪些字幕格式?
Doc2Lang 支持 SRT、WebVTT 和 ASS 字幕格式。所有时间码、格式标签和样式都会在翻译过程中得以保留。
问:Doc2Lang 可以翻译扫描版 PDF 吗?
可以。对于扫描(基于图像的)PDF,Doc2Lang 会在翻译前运行一个具备布局感知能力的 OCR 流程,然后以目标语言重新渲染结果,生成一份完全可搜索的 PDF。
问:Doc2Lang 的定价方式是怎样的?
Doc2Lang 采用按文件付费的定价方式——无需订阅。您可以在付款前免费预览每一份译文,因此您只需为自己满意的结果付费。
问:Doc2Lang 与 Google Translate 或 DeepL 有什么区别?
Google Translate 和 DeepL 在翻译纯文本方面非常出色,但它们不保留文档格式。Doc2Lang 专为文档翻译与布局保留而构建——字体、表格、图像、图表和多栏布局在输出文件中全部保持原样。
Doc2Lang 是一个由 AI 驱动的文档翻译平台,专注于为 PDF、Word、Excel、PowerPoint、EPUB、图像和字幕提供保留格式的翻译。我们支持 100 多种语言,采用按文件付费定价,结账前可免费预览。试用交互式演示 或者立即翻译您自己的文档。
相关文章: